
NTP server frequency stability
Stratum 2+ NTP servers have multiple potential sources of error, let's experiment with lowering them.
Why?
I've been asked why I'm interested in clocks and NTP. The reason is I like the idea of a giant number of computers and people, keeping everyone's clocks in the world in agreement1. It's a large number of people working together to achieve a goal, and that's important. Working on ways to improve NTP can help others, even if it is a small improvement. Plus it's a learning opportunity and a challenge to overcome.
Context
NTP servers all get their time from somewhere else. Servers directly connected to an external source (like a GPS receiver) are called stratum 1 and usually2 have the most accurate time.
For NTP servers that get their time from other NTP servers, they add 1 to their selected time source stratum. They start at stratum 2 and go up to a maximum of 16.
Stratum 2+ server challenges
Stratum 2+ servers have multiple sources of error when getting their time over the network from their upstream sources:
- local clock frequency change
- latency jitter
- asymmetrical latency
- outages
Local clock frequency change
Local clock frequency changes typically happen due to temperature changes. The crystals that drive CPU clocks are very sensitive to temperature and the CPU is a very efficient heater. Changes in CPU load can easily change the temperature (ex: ntpheat)
Latency Jitter
Latency jitter (or just "jitter") is the changes in latency between a NTP server and its upstream time source. Two example causes are network device queueing and NIC interrupt coalescing (blog link).
Asymmetrical latency
Asymmetrical latency is the difference in delay between the request and response from the NTP server to its upstream time source. This can come from things like the two packets taking different paths through the internet, more jitter in one direction than the other, and the design of the last mile network (especially cable modems and DSL).
There's no especially good way to control for asymmetric latency. Adding multiple sources that take different paths through the internet will help with a specific path asymmetry, but no amount of sources will help if the asymmetry is coming from the cable modem all requests go through.
Outages
If all of your upstream clocks go offline through some sort of internet outage or local network maintenance, it would be good to keep your local clock in sync until it can reach the upstream clocks again. Local clock frequency change will introduce errors and uncertainty the longer the outage.
Countermeasures - having a local time source
If you have a stratum 1 server on your local network, that can be an excellent source of time. Typically local networks are low latency, low jitter, and have little asymmetry. With hardware timestamps, it can even be precise enough to see the change in latency when using a different network switch.
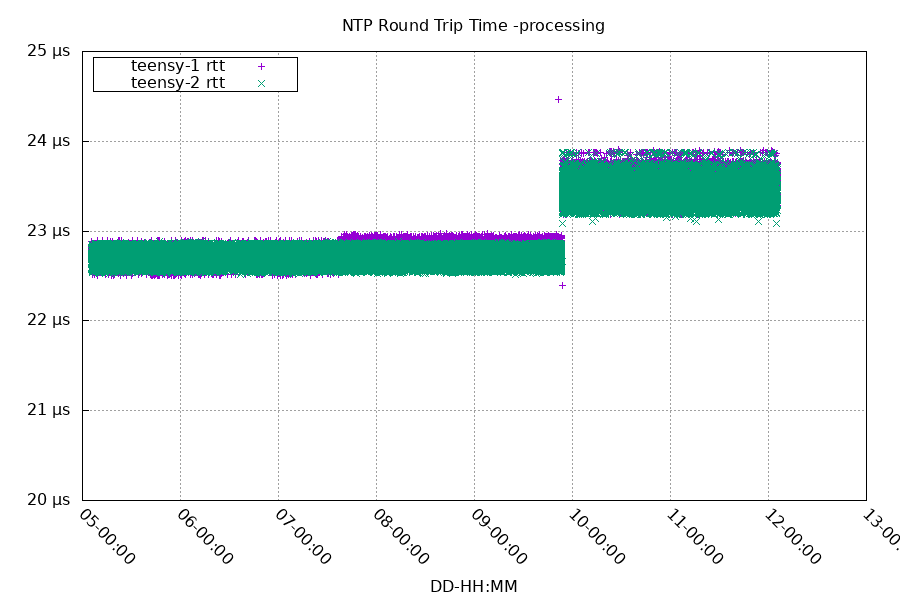
You can see the latency stays very stable with a given switch, around 0.5 microseconds of jitter.
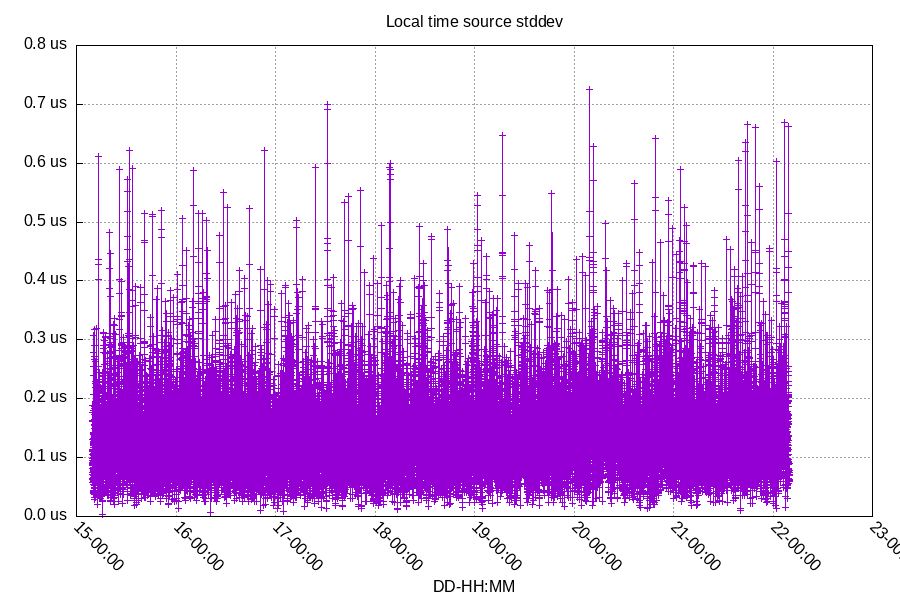
The standard deviation of time measurements are low as well, in the 100's of nanoseconds:
Clock offsets with this setup are very low, typically under 100 nanoseconds:
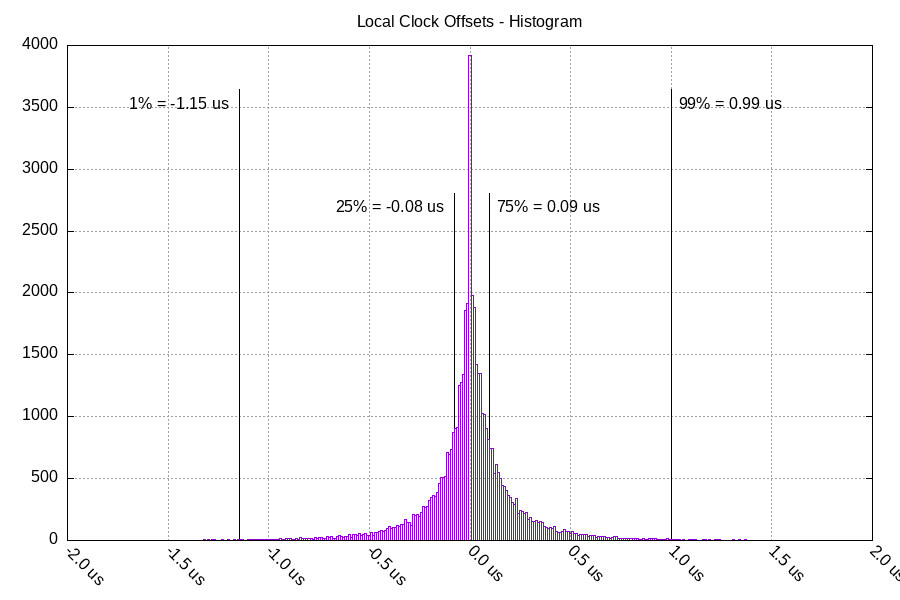
But it can be expensive to get a rooftop antenna on a datacenter, especially if it's someone else's building. So the majority of public stratum 2+ servers have a time source outside of their local network.
Countermeasures - without a local time source
To combat jitter without a local time source, the best countermeasure is to have a longer time between measurements. A 1ms uncertainty added by jitter is 1000ppm at 1 second measurement interval, but 1ppm at 1000 second interval. Combining multiple measurements over an even longer interval helps to keep the frequency error to a minimum. But having a long time between measurements is in direct conflict with local frequency change, which will add uncertainty as the time span goes up.
Having a way to limit local frequency change would be the biggest help to time synchronization. That's why I designed my TCXO raspberry pi hat. TCXOs are designed to have better frequency stability, even when the temperature changes. They are also useful when you have an upstream clock outage.
The NTP server software chrony recently added support for an external frequency source in the form of a pulse per second (PPS). The TCXO hat provides that PPS for the pi to keep its local clock on frequency.
Experiment 1 - no TCXO
Let's start with two upstream NTP servers, each about 10 milliseconds (10,000 μs) away. Compare that to the local lan stratum 1s' round trip time of 23.5 μs. Let's also configure the two stratum 1s on the local network as well as the TCXO, but leave them as unused ("noselect").
Relevant configuration file:
server stratum1-1.lan minpoll 0 maxpoll 4 xleave noselect
server stratum1-2.lan minpoll 0 maxpoll 4 xleave noselect
server ntp.linode.drown.org iburst
server ntp.vultr.drown.org iburst
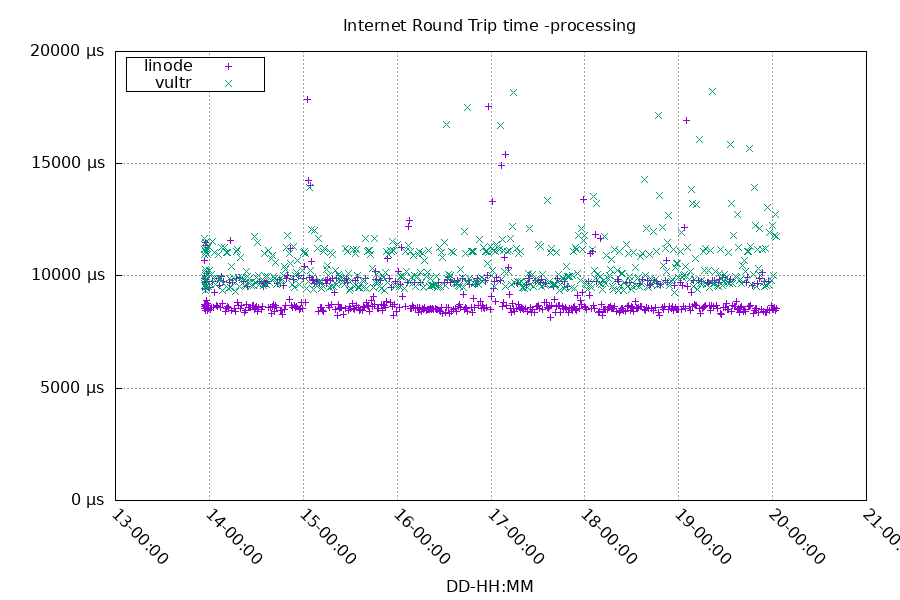
refclock PPS /dev/pps0 refid TCXO poll 3 dpoll 0 noselectFor the internet servers, sometimes the latency jumps much higher than 10 ms, and values over 20 ms are excluded from this graph to keep the scale reasonable.
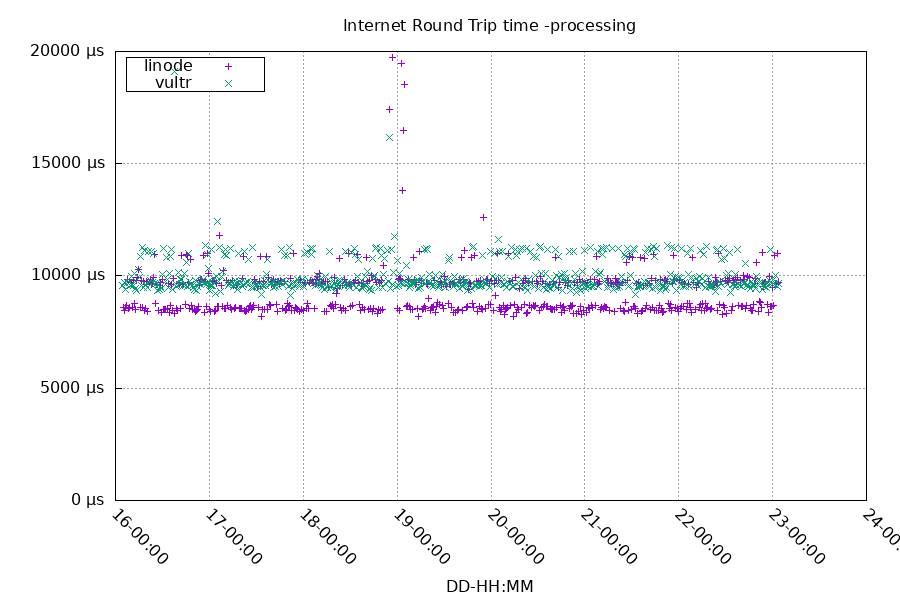
After letting it run that way for a week, we can look at the stratum 1 measurements to see how well the system's clock stayed in sync.
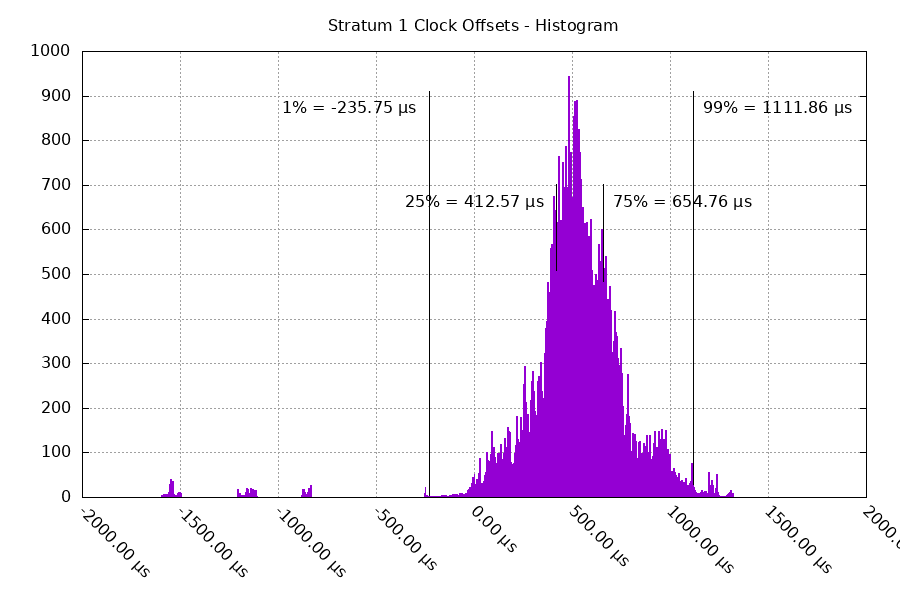
You can see here the asymmetrical latency coming into play. The asymmetry resulted in the clock being off by a mean value of 524 μs. The two other pieces, local clock frequency change and jitter, resulted in the clock having an offset between -236 μs and +1112 μs.
The local clock frequency change:
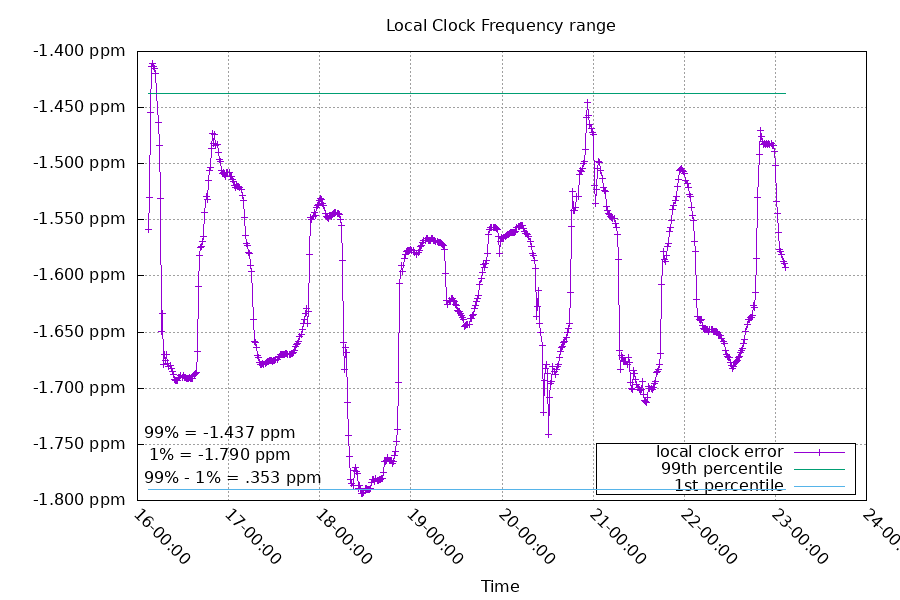
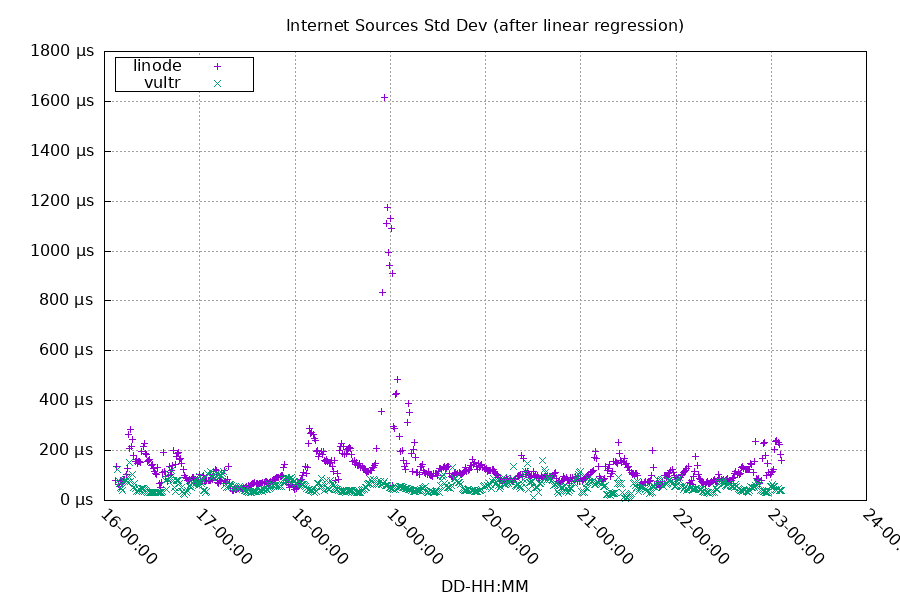
The local clock frequency error and the jitter combine to add uncertainty to the remote clock's measurement.
Experiment 2 - TCXO
Let's start with a similar config as before, but enable the local TCXO frequency reference:
server stratum1-1.lan minpoll 0 maxpoll 4 xleave noselect
server stratum1-2.lan minpoll 0 maxpoll 4 xleave noselect
server ntp.linode.drown.org iburst
server ntp.vultr.drown.org iburst
# using a TCXO, better than 0.1ppm
maxclockerror 0.1
# local TCXO reference
refclock PPS /dev/pps0 refid TCXO poll 3 dpoll 0 local maxlockage 128The round trip time to the sources was very similar:
The asymmetric latency hasn't changed, but the offsets are much narrower. The mean value is 472 μs (vs 524 μs), but the range is a much narrower +309 μs to +628 μs (vs -236 μs and +1112 μs).
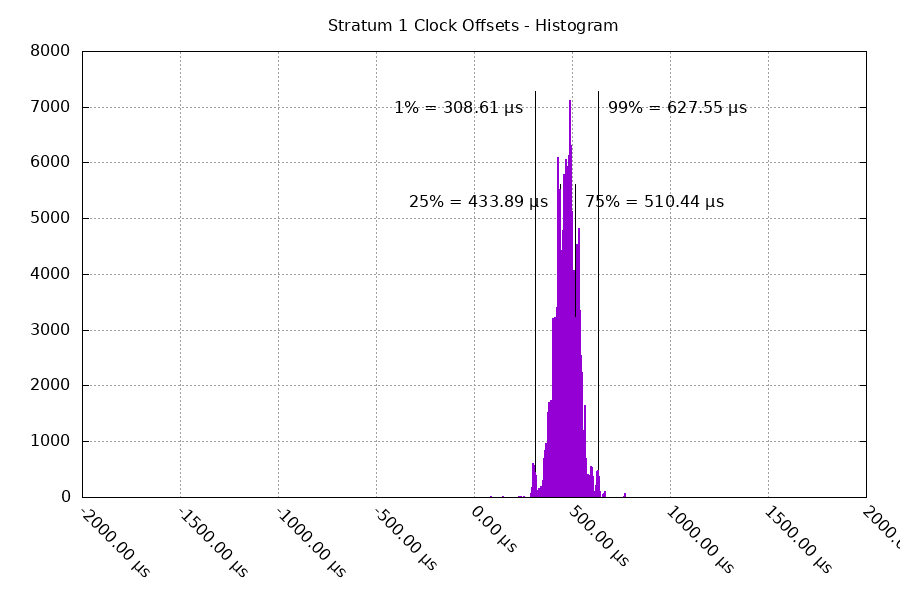
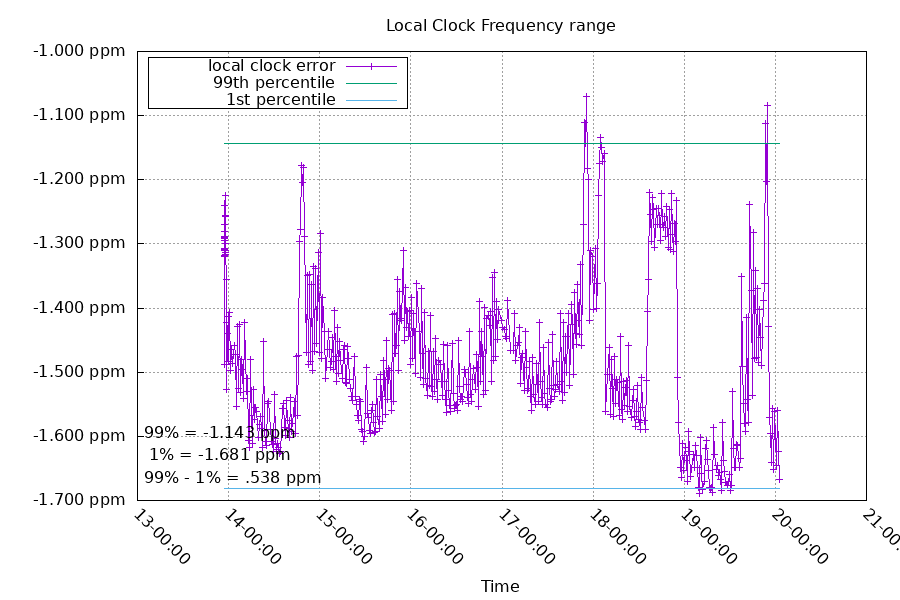
The local clock frequency change is much more high frequency - because the local TCXO is correcting the local clock frequency much faster than polling an upstream source with the default intervals. This keeps the local clock offset lower.
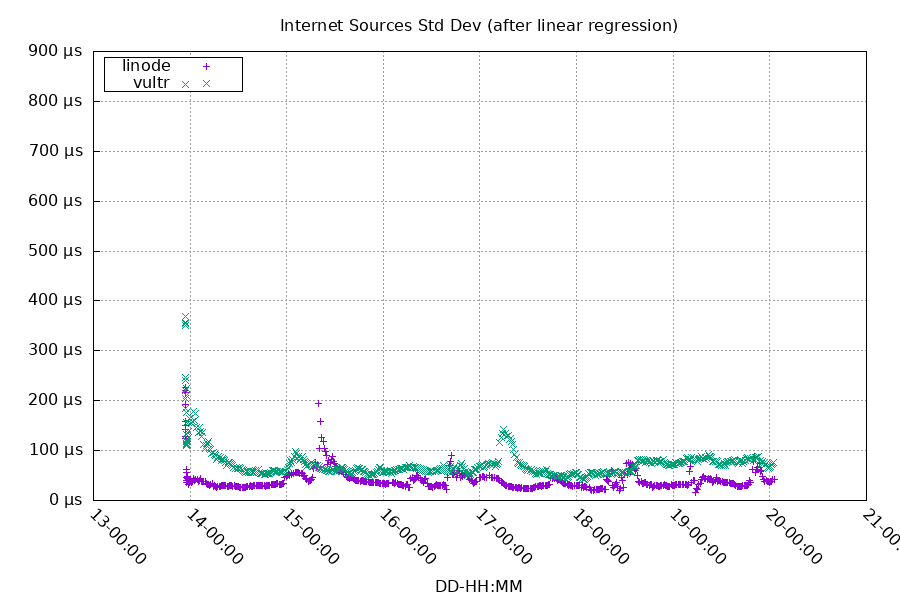
And lastly, the remote clock uncertainty was reduced as well. Both the average (from 95 μs to 60 μs) and the high frequency spikes as well (99th percentile from 423 μs to 220 μs).
Summary
Having a local frequency reference is an improvement for stratum 2+ NTP servers. It keeps the local clock closer to the true time through reducing the impact of jitter and local clock frequency changes. It is also helpful during an outage of all of your upstream time sources.
Footnotes
- For some values of "in agreement" and "everyone's clocks"
- Usually but not always
Other Links
- NTPHeat blog post 1
- NTPHeat blog post 2
- Chrony Graphs
- Local Stratum 1 NTP servers
- TCXO hardware + firmware
Questions? Comments? Contact information