
TCXO RTC Raspberry Pi Hat, part 2
The motivation for this project is NTP servers in datacenters - it can be expensive to get a GPS antenna on top of other people's buildings with a wire running down into your rack. The question is, how do you maximize the accuracy of a stratum 2 NTP server?
The first problem to solve is time sources. Ideally, they would be close network wise, and provide accurate time to the microsecond range over the network. This is possible on a small local network, but is less likely over the general internet. I'll leave that topic for a different blog post.
The second problem is local clock stability. The more stable your local clock, the lower the impact of any issues (packet loss, jitter, and temporary latency asymmetry) with your time sources. That's what I'll focus on here.
Local clock stability
Continuing from TCXO RTC Raspberry Pi Hat, my goal is to increase the local clock's stability by locking the system clock's frequency to a TCXO via a PPS input.
The steps I listed on the part 1 post for me to complete:
- converting my RTC firmware from PWM input to PPS output - on github as the branch "output"
- having the RTC firmware do the temperature compensation (instead of the system) - local frequency estimate calculated every second and applied to PPS output, calculated at sub-nanosecond offsets and then dithered by the local 48MHz time base
- updating the i2c registers to include relevant state - client to dump all i2c register data
- making sure my systems have the pps-gpio kernel module - stm32mp1 kernel module
- updating my devicetrees to connect the pps-gpio module to the RTC hat's PPS output - stm32mp1 device tree patch & odroid c2 device tree overlay
- running chrony with a "local refclock" - see next section
Running chrony with a local refclock
I compiled chrony from git and started with the configuration of using my local stratum 2 (sandfish) and noselect applied to my two local stratum 1s (teensy-$N):
server sandfish.lan xleave iburst
server teensy-1.lan minpoll 0 maxpoll 4 xleave noselect
server teensy-2.lan minpoll 0 maxpoll 4 xleave noselect
hwtimestamp *
clientloglimit 1000000
# using a TCXO, better than 0.1ppm
maxclockerror 0.1
# local TCXO reference
refclock PPS /dev/pps0 refid TCXO poll 3 dpoll 0 local maxlockage 128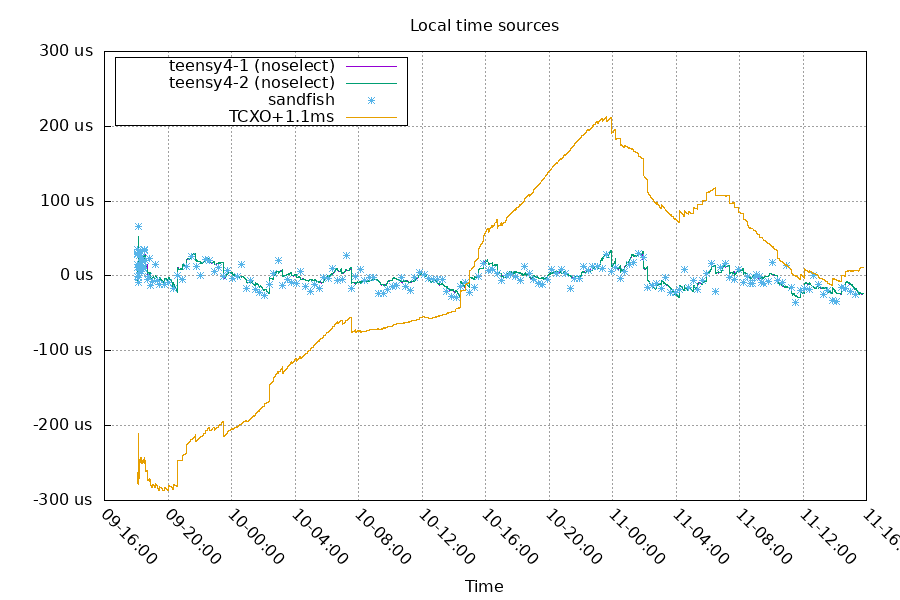
This looks fine, but it's hard to separate the contribution of the TCXO from the normal state of the system.
Next run, I set sandfish to a fixed poll interval of 1024 seconds to make the TCXO contribution more important. Now any small frequency difference will show up more obviously.
Upstream clock outage
During this test, the sandfish.lan server crashed and was down for a little over 14 hours. So I got to test the system's holdover performance.
First, the last 7 samples with the crash around 11:30:
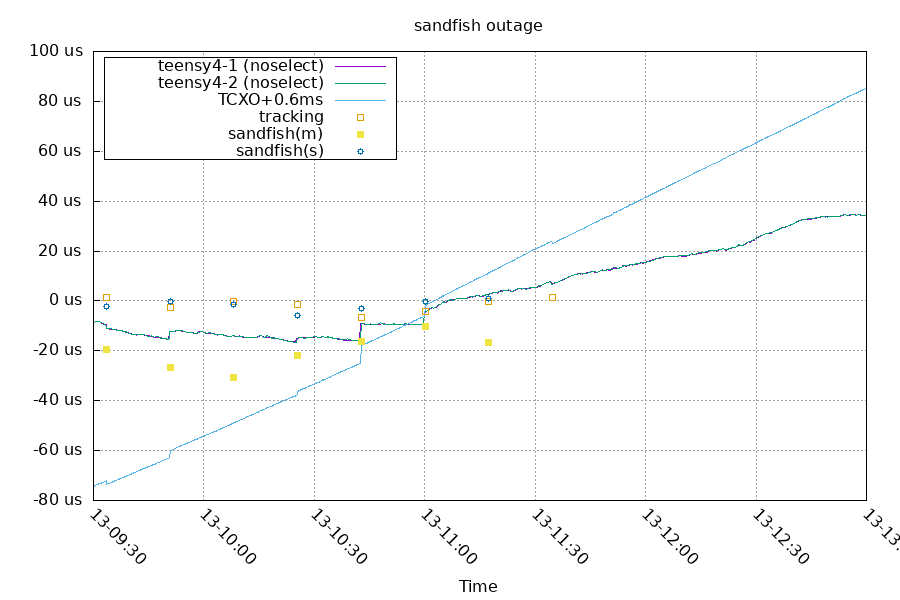
The system clock started with an offset under 10us. The steps in offset before 11:30 are chrony changing the local time to stay in sync with the measurements from sandfish. After 11:30, you can see the system doesn't blindly trust the TCXO's frequency, but keeps the system at a set frequency relative to it.
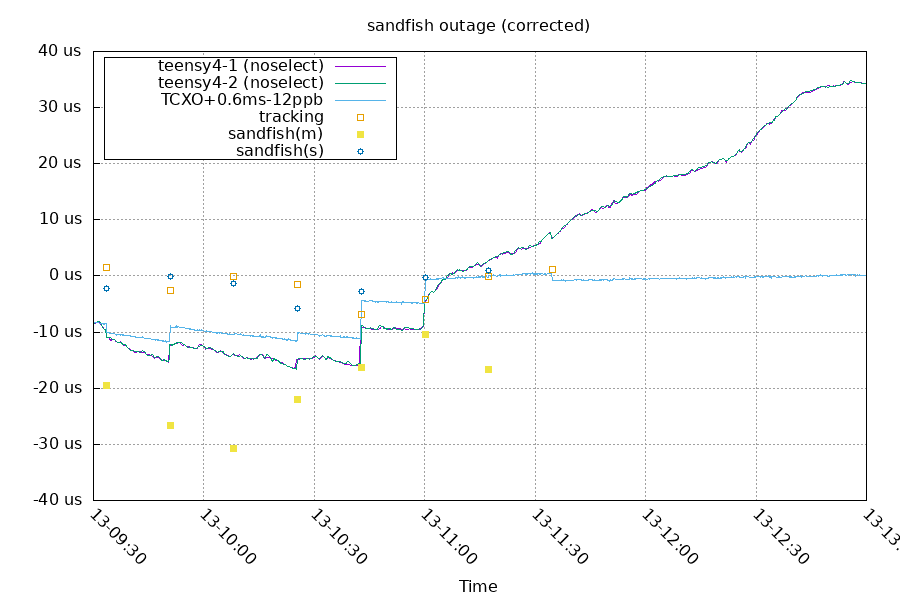
The system subtracted (slowed) the TCXO's frequency by about 12 ppb and stayed in sync with it. From the teensy-$N server data, we can estimate the system clock was around 4ppb slow (35us in 2 hours)
After sandfish came back online, the system's time jumped around a lot. I assume this was an artifact of the forced high poll interval, but I do need to experiment with this some more. The system did eventually get back into normal offsets under +/-10us.
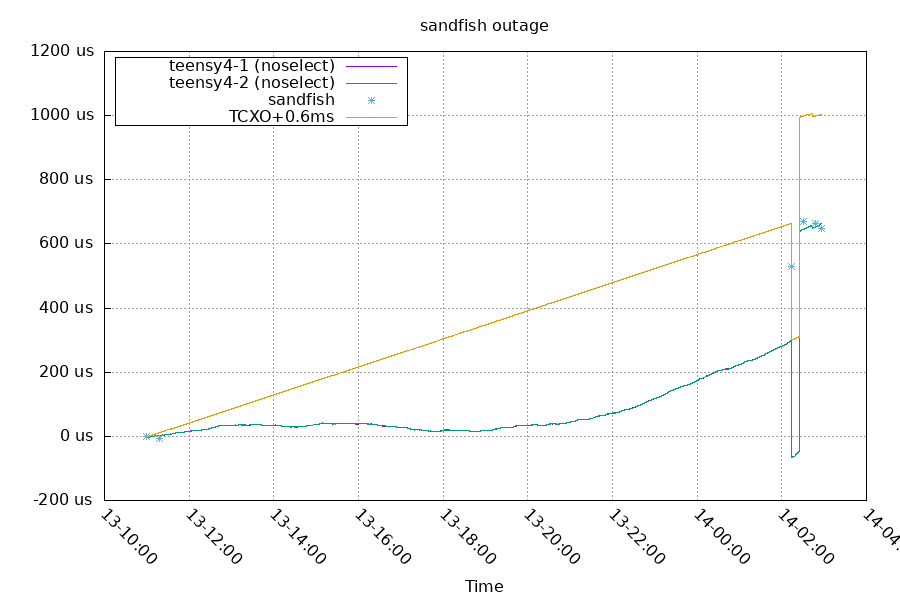
Messing with the TCXO's timebase
The chrony logfiles only have 4 digits of precision. When I moved one of the systems with the rtc hat to another location, it powered on with the PPS at around 178ms offset. The chrony log precision at that offset is 100us steps, which makes the graphs look like stair steps.
I moved the hat PPS closer to an offset of 0ms to make the logs look nicer, and the system followed it closely. This creates havoc for awhile till the system settles back down to normal polling.
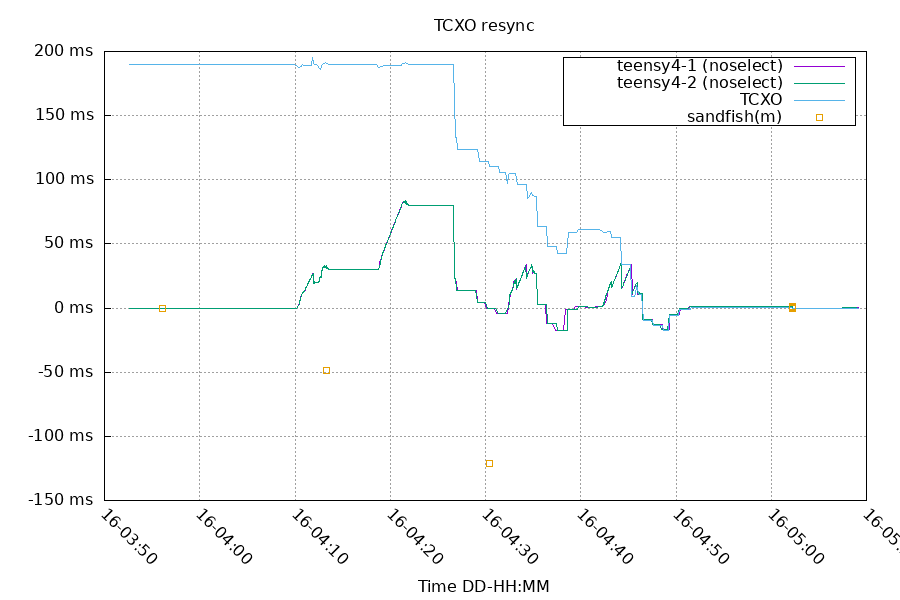
At around 4:10, I started changing the TCXO's offset. By default, the TCXO firmware adjusts offsets at a maximum rate of +/-200ppm. You can see the system just follows the TCXO and keeps the offset between the system and TCXO flat, while the real offset is showing up with the teensy-$N lines. The system only polled sandfish 4 times in this entire timeframe, and it took almost 20 minutes for it to realize there was a large offset to start correcting. It took another 20 minutes to get back into normal sync.
Takeaway from this is: when you use a local frequency reference, it can't jump around.
Next steps
I'll run this for another few weeks to see how it acts. I'd also like to start estimating the effects of crystal aging on frequency.
Questions? Comments? Contact information