
Event Loop Software
The simple description of an event loop is a program waits for an external event from many different sources, does some processing on that event, and then waits for the next event. It is a common architecture in many different types of software. This blog post will go into the low level details of how they interact with the kernel.
The event loop is efficient at io limited workloads but not as good at cpu limited workloads. It is built around the assumption that the processing done on each event is tiny relative to the time spent waiting for events. This is true for things like web browsers, some types of web servers, messaging applications, and anything that spends most of its time waiting for traffic or user input. Things that would not work well as an event loop would be video encoding, large file compression, and machine learning. However, those things could be organized by an event loop and performed in a separate thread.
Nginx
The nginx web server uses an event loop and can handle thousands of connections at the same time with relatively low memory and cpu usage. Since it does minimal amounts of processing for each request, it can handy many connections at the same in the same process.
Below is a simplified diagram of nginx handling a http request for a static file. Dynamic content and TLS work differently, but this is a good starting point. These are system calls, which nginx uses to talk to the outside world.
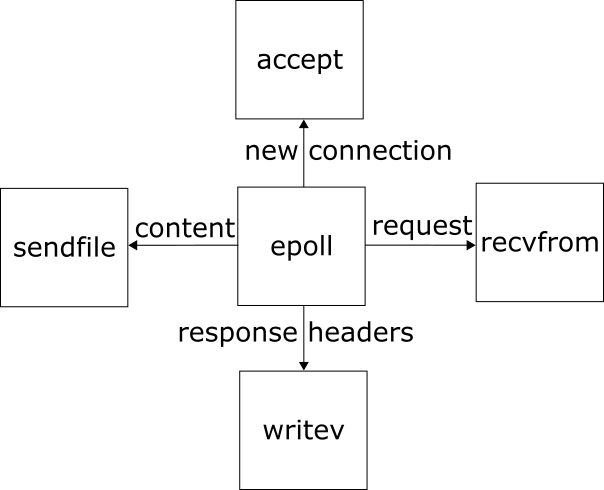
epoll is the center of nginx's event loop on Linux. It waits for any network activity and lets nginx know which connection needs attention.
For our example of a http request of a static file, the events are:
- new connection: nginx uses accept to accept the new connection
- request: nginx uses recvfrom to read data from the connection
- sending response headers: nginx uses writev to write all the headers at once (data comes from memory)
- sending content: nginx uses sendfile to send the static file over the connection (data comes from filesystem)
I've skipped over some details. If you want to see the full list of system calls, use strace on a copy of nginx and request a static file from it.
Between each of these events, nginx goes back to waiting in epoll. Since all of these operations are done with non-blocking IO, nginx doesn't spend a lot of time handling each of these events and can quickly get back to waiting in epoll.
Node.js
Node.js also is built around an event loop. If I take a trivial example program that waits for three different timers to expire, 1 second apart:
async function sleep(millis) {
return new Promise((resolve) => setTimeout(resolve, millis));
}
async function main() {
const events = await Promise.all([sleep(1000), sleep(2000), sleep(3000)]);
console.log("done waiting for events");
}
main();
The strace output of node running this program is very long, so these are just the key system calls:
epoll_wait(13, [], 1024, 994) = 0
epoll_wait(13, [], 1024, 992) = 0
epoll_wait(13, [], 1024, 998) = 0
write(17, "done waiting for events\n", 24) = 24
epoll_wait waits for either IO activity or a timeout. It is waiting for ~995 milliseconds instead of 1000 because it's doing some other work as well that took 2-8 milliseconds to complete between the epoll_wait calls. Since there was no IO activity for this example, it was just waiting for the timers. It was waiting for each timer in parallel, so instead of 1000 ms+2000 ms+3000 ms total time, it took 3000 ms total time.
This program could have been waiting for webservice results, a database, a message queue, or some other sort of IO as well as a timeout.
Conclusion
Now you know more about how event loops are implemented and what their strengths and weaknesses are. Go out and use them every day in a variety of different software!
Questions? Comments? Contact information